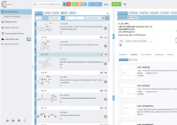
ChemAudit: An Open-Source Chemical Structure Validation Suite

Brings structure validation, standardisation, structural alert screening, and quality scoring together in one interface.
Brings structure validation, standardisation, structural alert screening, and quality scoring together in one interface.
The article reports on the experiences gained with the introduction of an ELN at the University of Würzburg.
The winners of the FAIR4Chem Award have now been announced. Once again, we have two winners this year.
News from our tools – the next steps with our ELN and Repositories.
“Hot Paper” in Phys. Chem. Chem. Phys.: Challenge combining molecular property predictions with peer evaluation of data FAIRness.
The primary aim was to advance a shared, community-governed “ontology canon”, understood as a set of recommended chemical ontologies.
The new release brings key improvements to research data access and integration.
The ELIXIR BioHackathon Europe took place 3–7 November 2025 in Bad Saarow near Berlin.
Further planning meeting of the Coalition for the Sustainability of Digital Data Standards in the Chemical Sciences.
Ann-Christin Andres spent two months at TU Denmark as part of a fellowship. Here is her report.