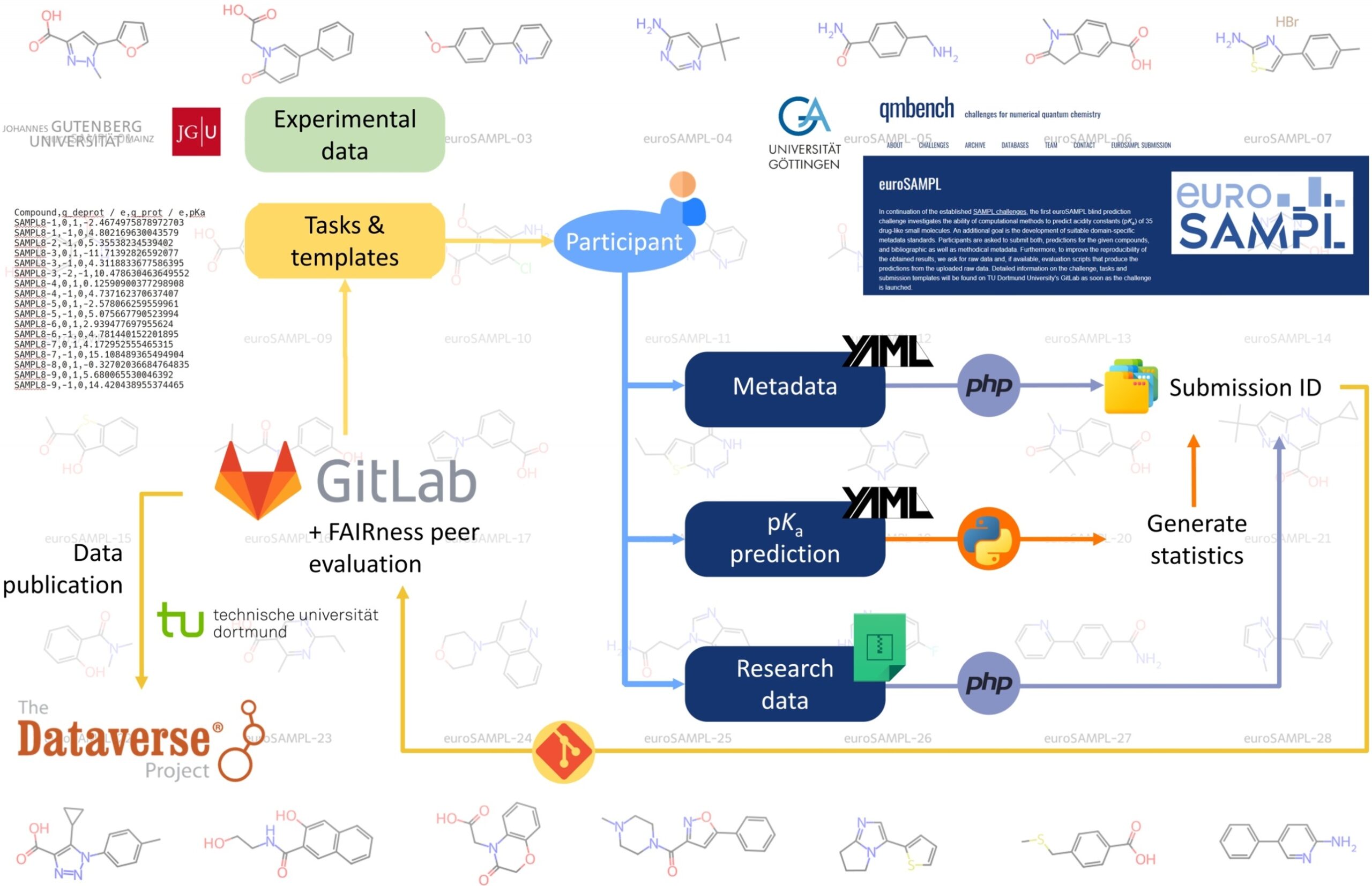
The NFDI4Chem-supported euroSAMPL challenge combined molecular property predictions with peer evaluation of data FAIRness
The first and now finished euroSAMPL challenge, organized by Stefan Kast, Ricardo Mata, and Paul Czodrowski, was established to continue the SAMPL (Statistical Assessment of Modeling of Proteins and Ligands) series of molecular property prediction blind challenges using computational models.
The current euroSAMPL round was devoted to the prediction of aqueous pKa values of small drug-like molecules provided as SMILES strings and, as a novel challenge component, included a peer evaluation of submissions concerning FAIR criteria as well as reproducibility. Details and analyses are found at https://gitlab.tu-dortmund.de/kast_ccb/eurosampl/challenge; see https://www.youtube.com/watch?v=jhvGx3gaZTc for an overview.
The community will have the opportunity to discuss the challenge results during the 18th German Conference on Cheminformatics (GCC 2024 ) in November.